Mapping Embeddings 🗺️🔍
From meaning to vectors and back
$$\left|\text{🧠}\right>$$
Contents 📓
- Introduction to Embeddings
- Working with Vector Databases
- Dimensionality Reduction Techniques
- Advanced Retrieval Strategies
- Retrieval Augmented Generation (RAG)
Warning ⚠️
This deck is a work in progress…
and always will be
Feel free to search around 🔎

Cite this presentation 📑
@misc{a-tour-of-genai-jgalego,
title = {Mapping Embeddings: from meaning to vectors and back},
author = {Galego, João},
howpublished = \url{jgalego.github.io/MappingEmbeddings},
year = {2024}
}Note on implementation 👨💻
The slides were created using reveal.js
and the presentation is hosted on GitHub Pages
Want to contribute? ✨
Just open an issue/PR for this project
github.com/JGalego/MappingEmbeddings
Introduction to Embeddings
Let's start by sending some love
to Amazon Titan for Embeddings...

Titan Love 🔱💗
"""
Sends love to Amazon Titan for Embeddings 💖
and gets a bunch of numbers in return 🔢
"""
import json
import boto3
# Initialize Bedrock Runtime client
# https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/bedrock-runtime.html
bedrock = boto3.client("bedrock-runtime")
# Call Amazon Titan for Embeddings model on "love"
# https://docs.aws.amazon.com/bedrock/latest/userguide/titan-embedding-models.html
response = bedrock.invoke_model(
modelId="amazon.titan-embed-text-v1",
body="{\"inputText\": \"love\"}"
)
# Process the model response and print the final result
body = json.loads(response.get('body').read())
print(body['embedding'])
WTF?

Where is the love?

Let's put this question on hold for now...
and work out some definitions.
What are embeddings?
A numerical representation of a piece of information

Example: Embedding Wikipedia
What if you had the embeddings of ALL Wikipedia?


Example: Amazon Music
Neighboring vectors, similar tracks

Example: Embedding Projector
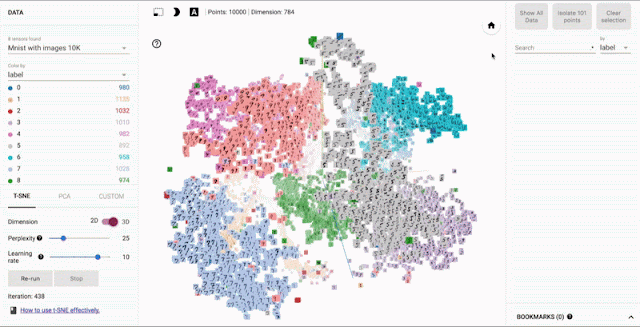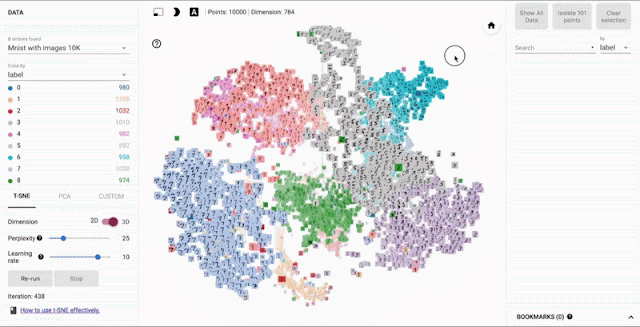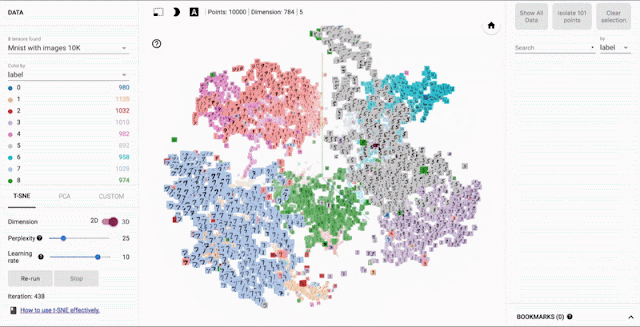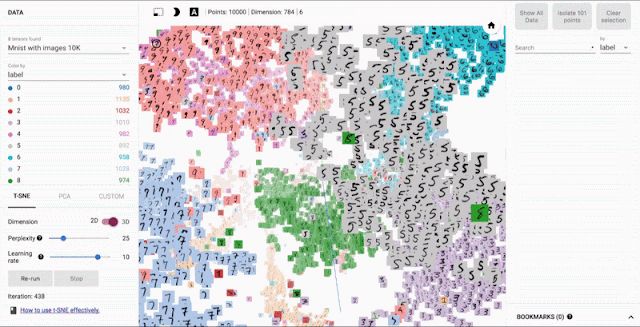
Example: AI Virtual Cell

Data $\rightarrow$ "meaningful" numbers
Now, let's get back to our original example...
Why love?

Rule of thumb: 1 token ~ 4 characters
You may have heard of the
$\texttt{1 token} \sim \texttt{4 chars}$ rule of thumb
Well, things are a bit more complicated than that...
so let's spend a few tokens on tokenization
Tokenization is the root of (almost) all evils

Some are just plain 𝚠𝔢𝒾𝐫𝔡...

Tokenization is one of the reasons why LLMs
are usually bad at math...

Tiktokenizing integers

Replicating Integer Tokenization is Insane 🤯



All languages are not created tokenized equal!


Ok, time to head back to our main feature...

How do we actually train an embedding model?
Image Embeddings 🖼️
Contrastive Learning

Distance Measures

Train an Image Embedding model from scratch
# pylint: disable=import-error,invalid-name
"""
Train image embeddings model from scratch using contrastive learning.
Adapted from Hadsell, Chopra & LeCun (2005)
https://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf
and Underfitted's 'Training a model to generate image embeddings'
https://underfitted.svpino.com/p/training-a-model-to-generate-image
"""
import numpy as np
from keras import datasets, Input, Model
from keras.layers import Dense, Lambda
from keras.metrics import binary_accuracy, BinaryAccuracy
from keras.models import Sequential
from keras.ops import cast, maximum, norm, square
########
# Data #
########
# Load dataset
(X_train, y_train), (X_test, y_test) = datasets.mnist.load_data()
# Reshape and normalize it
X_train = X_train.reshape(-1, 784)
X_test = X_test.reshape(-1, 784)
X_train = X_train.astype('float32') / 255.0
X_test = X_test.astype('float32') / 255.0
def generate_pairs(X, y):
"""
Creates a collection of positive and negative image pairs.
"""
X_pairs = []
y_pairs = []
for i in enumerate(X):
digit = y[i]
# Create positive match
positive_digit_index = np.random.choice(np.where(y == digit)[0])
X_pairs.append([X[i], X[positive_digit_index]])
y_pairs.append([0])
# Create negative match
negative_digit_index = np.random.choice(np.where(y != digit)[0])
X_pairs.append([X[i], X[negative_digit_index]])
y_pairs.append([1])
# Shuffle everything
indices = np.arange(len(X_pairs))
np.random.shuffle(indices)
return np.array(X_pairs)[indices], np.array(y_pairs)[indices]
# Prepare input pairs
X_train_pairs, y_train_pairs = generate_pairs(X_train, y_train)
X_test_pairs, y_test_pairs = generate_pairs(X_test, y_test)
#########
# Model #
#########
# Define inputs
input1 = Input(shape=(784,))
input2 = Input(shape=(784,))
# Build siamese network
network = Sequential(
[
Input(shape=(784,)),
Dense(512, activation="relu"),
Dense(256, activation="relu"),
Dense(128, activation=None),
]
)
# Define twin branches
twin1 = network(input1)
twin2 = network(input2)
# Define distance
def euclidean_distance(a, b):
"""Computes the Euclidean distance."""
return norm(a - b, axis=1, keepdims=True)
distance = Lambda(euclidean_distance)(twin1, twin2)
# Set up the model
model = Model(inputs=[input1, input2], outputs=distance)
########
# Loss #
########
def contrastive_loss(y, d):
"""
Computes the contrastive loss from Hasdell, Chopra & LeCun (2005)
"""
margin = 1.0
y = cast(y, d.dtype)
loss = (1 - y) / 2 * square(d) + y / 2 * square(maximum(0.0, margin - d))
return loss
# Compile model using contrastive loss
model.compile(
loss=contrastive_loss,
optimizer="adam",
metrics=[binary_accuracy]
)
#########
# Train #
#########
# Fit the model
history = model.fit(
x=[X_train_pairs[:, 0], X_train_pairs[:, 1]],
y=y_train_pairs[:],
validation_data=([X_test_pairs[:, 0], X_test_pairs[:, 1]], y_test_pairs[:]),
batch_size=32,
epochs=5,
)
########
# Test #
########
# Generate predictions
predictions = model.predict([X_test_pairs[:, 0], X_test_pairs[:, 1]]) >= 0.5
# Compute model accuracy
accuracy = BinaryAccuracy()
accuracy.update_state(y_test_pairs, predictions.astype(int))
print(f"Accuracy: {accuracy.result().numpy():.2f}")
############
# Generate #
############
# Initialize model
embedding_model = model.layers[2]
# Generate embeddings
digits = np.where(y_test == 7)[0]
embeddings = embedding_model.predict(X_test[np.random.choice(digits)].reshape(1, -1))
print(embeddings, len(embeddings))
Sentence Embeddings 💬
Step 1: Model
pip install -q sentence-transformersThere are plenty to choose from on 🤗

Step 2: Data + Loss Function

Step 3: Test
MTEB: Massive Text Embedding Benchmark

How good/bad is Amazon Titan for Embeddings?
* Inspired by Phil Schmid's postOctober 2023: amazon.titan-embed-text-v1

September 2024: amazon.titan-embed-text-v2:0

Are bigger embeddings always better?
Well, not necessarily...Matryoshka Representation Learning 🪆

Working with Vector Databases
Quote #1
"The most important piece of the preprocessing pipeline, from a systems standpoint, is the vector database."Andreessen Horowitz
Quote #2
"In the future, we believe that every database will be a vector database."Google
Vector databases are everywhere
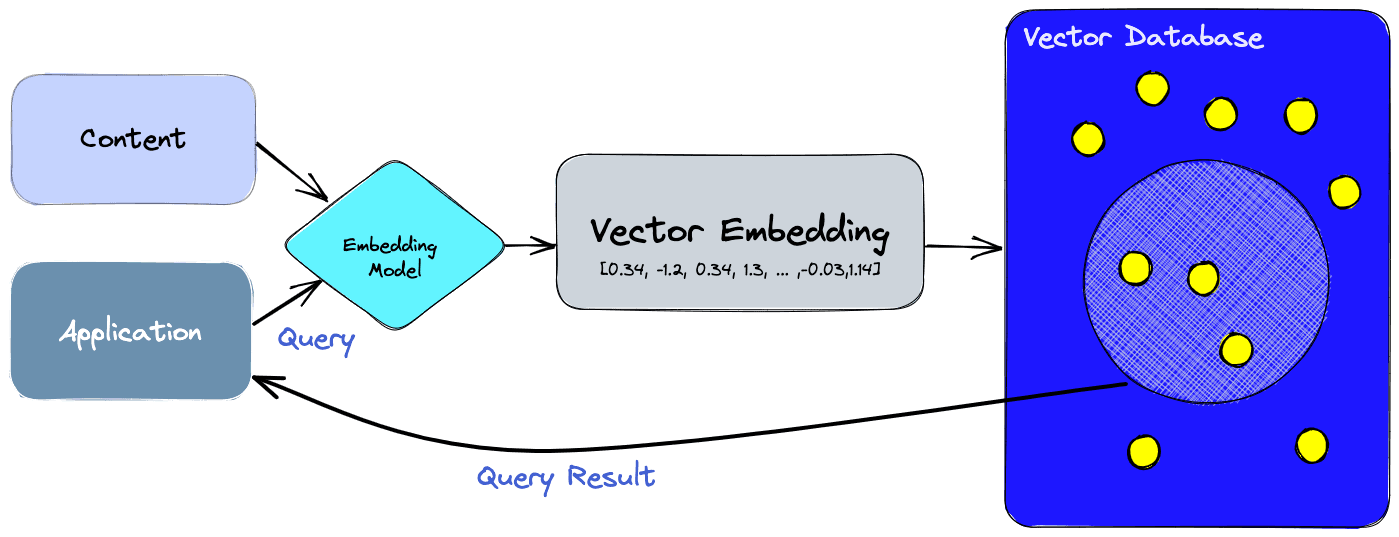
But... what are they?
Any database that treats vectors as first class citizens is a vector database.
CR7 Embeddings ⚽

Vector Database Types

Vector Databases on AWS
Demo: SQLite + Amazon Bedrock
Multimodal vector search with sqlite-rembed

Mind the (multimodal) gap!

Modality Gap Explorer 🧭

Language Gap Explorer 💬🧭

Dimensionality Reduction Techniques

Dimensionality reduction is used to
make sense of high-dimensional data

It can bring huge benefits...
- Compute / Storage ⬇️
- Data Visualization ✨
It comes in many flavors...
- global 🆚 local
- linear 🆚 non-linear
- parametric 🆚 non-parametric
- deterministic 🆚 stochastic
We'll focus on 3 different techniques...
Embedding a 2D circle with t-SNE

Initialization is critical

Dimensionality reduction as probabilistic inference

The map is not the territory!


Von Neumann's Elephant Woolly Mammoth


Now, you may be wondering...
How do models represent more features
than they have dimensions?
Let's talk about Superposition
(not the quantum type)Superposition Hypothesis

The Hunt for Monosemanticity

Example: Golden Gate Bridge 🌉

Example: Golden Gate Bridge 🌉

Example: Golden Gate Bridge 🌉

Example: Golden Gate Bridge 🌉

Advanced Retrieval Strategies

When (naive) vector search fails!

RAG Triad

Advanced Retrieval Techniques
- Query transformations
- Generated answers
$\texttt{query} \rightarrow \texttt{LLM} \rightarrow \texttt{hypothetical answer}$ - Multiple queries
$\texttt{query} \rightarrow \texttt{LLM} \rightarrow \texttt{sub-queries}$ - Cross-encoder re-ranking
- Embedding adaptors
- Other techniques
- Fine-tune embedding model
- Fine-tune LLM for retrieval (RA-DIT, InstructRetro)
- Deep embedding adaptors
- Deep relevance modelling
- Deep chunking
RAG Fusion

Demo: RAGmap 🗺️🔍
RAGxplorer 🦙🦺
A simple tool for RAG visualizations

First major bug!

RAGmap 🗺️🔍
Visualization tool for exploring embeddings

RAG in a nutshell 🥜
- LLMs are trained on HUGE amounts of data, but...
- LLMs haven't seen your data
- RAG is key to connecting LLMs to external data
RAG Stages
- Load
- Index
- Store
- Query
- Evaluate
- Update

Let's look at an example...
Step 1: Load

Step 2: Index + Store


Step 3: Query

Step 4: Evaluate



Key Takeaways

In summary...
- Embedding models turn data into "meaningful" numerical representations (vectors)
- Vector databases can be used to search through these representations efficiently
- Dimensionality reduction allows us to to make sense of high-dimensional data
- Advanced retrieval strategies can be a great asset when naive search is not enough
- RAG ties everything together by bringing external data to the model but...
- It's still just a clever hack!
- There's much we don't know...
HIC SVNT DRACONES 🐉


What we don't know...
💧
"What we know is a drop,Isaac Newton
what we don't know is an ocean."
References 📚

General
- (Modern Coding) Introduction to embeddings (vectors) and how they work
- (StackOverflow) An intuitive introduction to text embeddings
- (Hugging Face) Getting Started with Embeddings
- (Zilliz) An Introduction to Vector Embeddings: What They Are and How to Use Them
- (Weaviate) Step-by-Step Guide to Choosing the Best Embedding Model for Your Application