A Tour of GenAI 🚀
There and back again...
Contents 📓
- GenAI in a nutshell 🌰
- Building GenAI on AWS
- GenAI in practice
- References
Warning ⚠️
This deck is a work in progress…
and always will be
Feel free to search around 🔎

Cite this presentation 📑
@misc{a-tour-of-genai-jgalego,
title = {A Tour of GenAI},
author = {Galego, João},
howpublished = \url{jgalego.github.io/GenAI},
year = {2023}
}Note on implementation 👨💻
The slides were created using reveal.js
and the presentation is hosted on GitHub Pages
Want to contribute? ✨
Just open an issue/PR for this project
github.com/JGalego/GenAI
GenAI in a nutshell

In the beginning
there was nothing *,
which exploded…
― Terry Pratchett, Lords and Ladies (1992)
💥

* Well, not exactly…
History has a way of repeating itself...

{kind=link}
1960s: The ELIZA Effect

2022: The ChatGPT Effect

Can you spot the differences?
👀Let's back up a little…

2017: Hello Transformers!
Attention Is All You Need introduces the
Transformer architecture
Motivation
Previous seq2seq models were
SLOW 🐌 and FORGETFUL 🤔
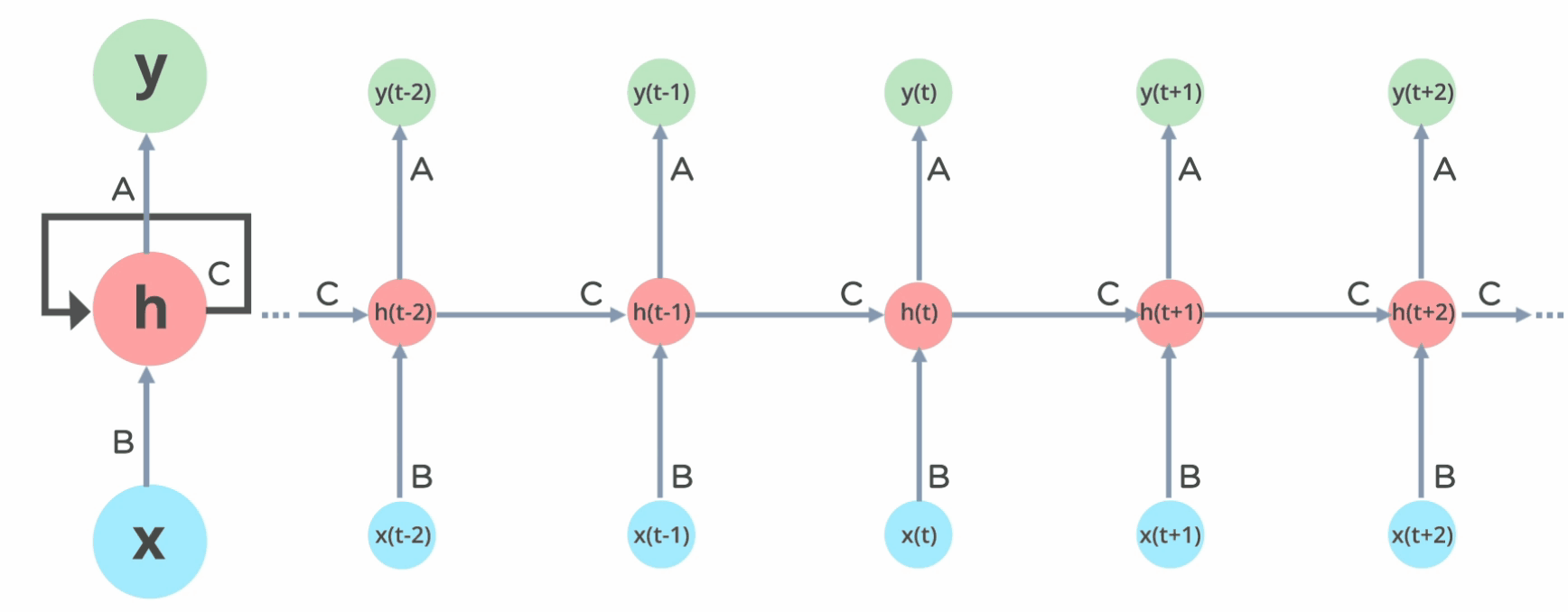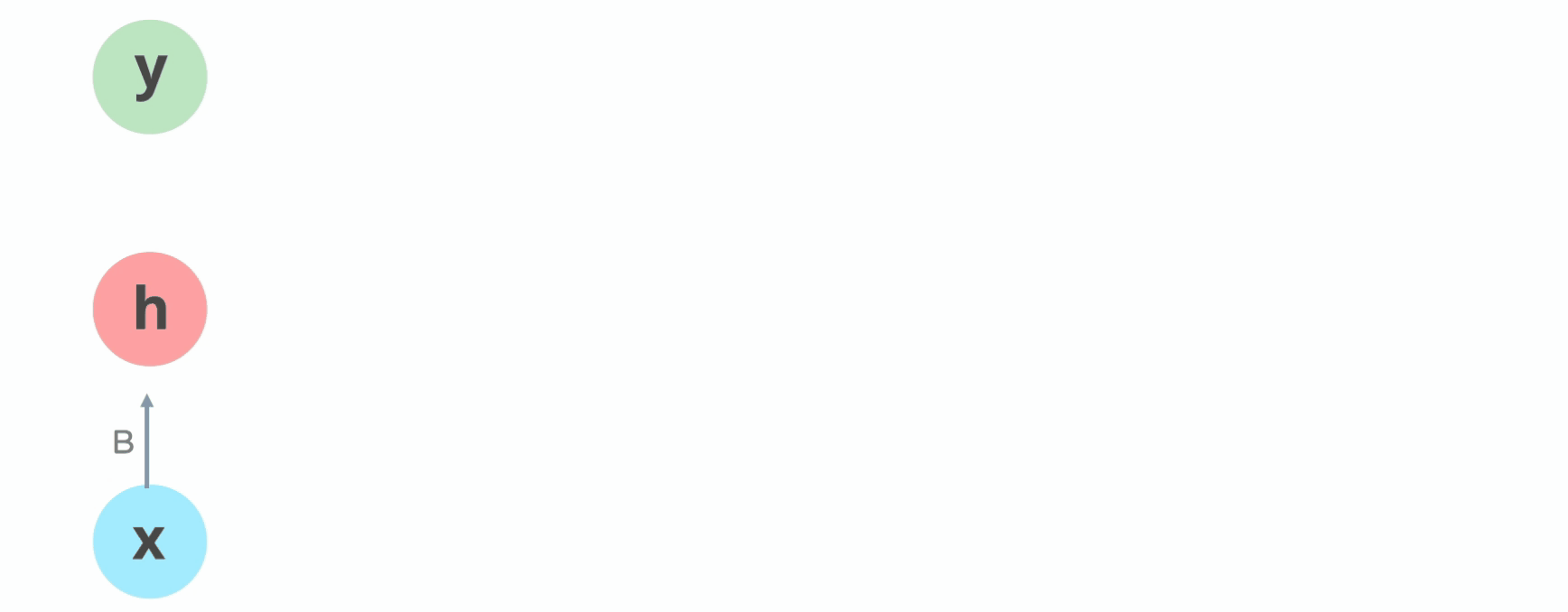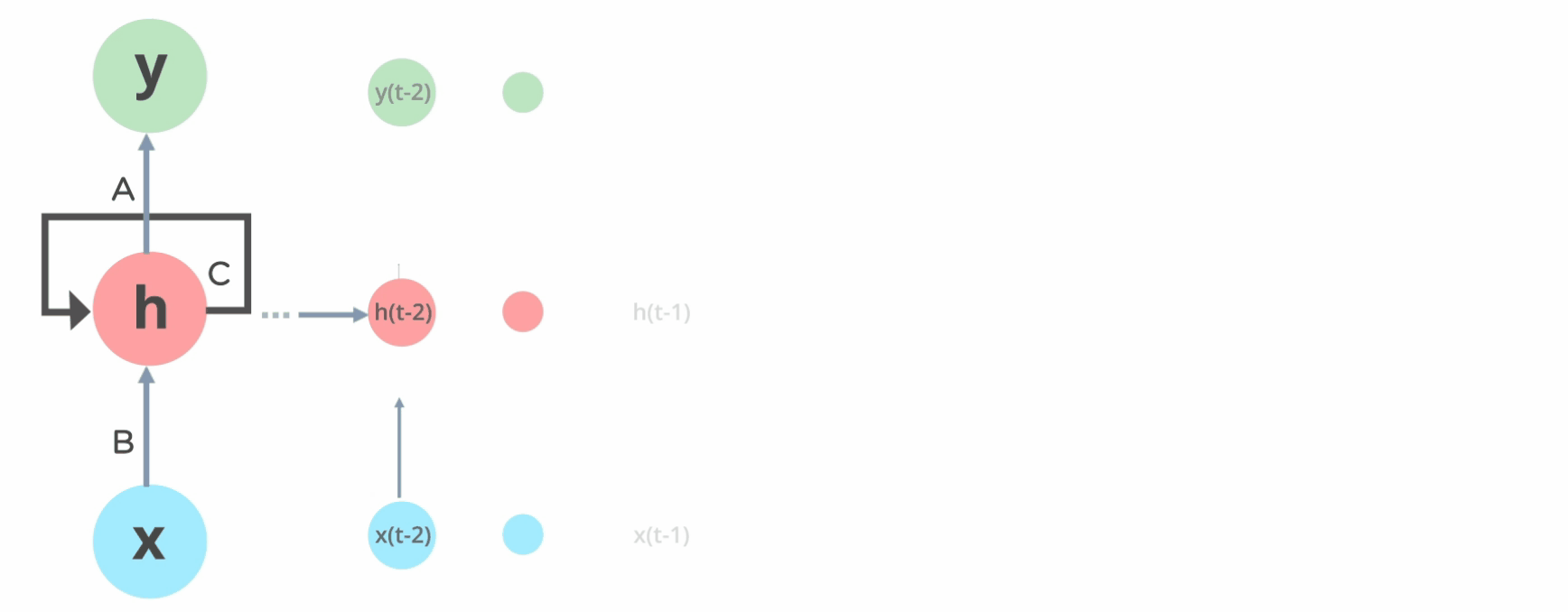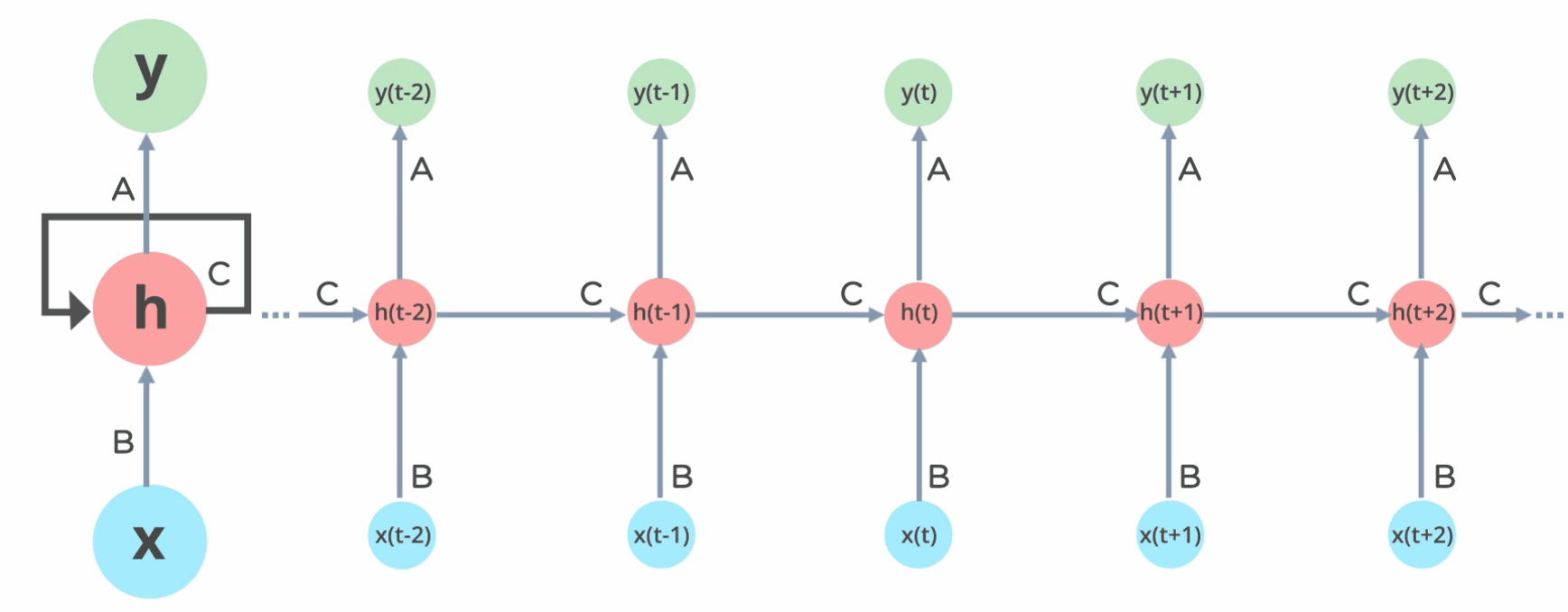
Transformers use
an encoder-decoder architecture…
… made of many building blocks 🧱
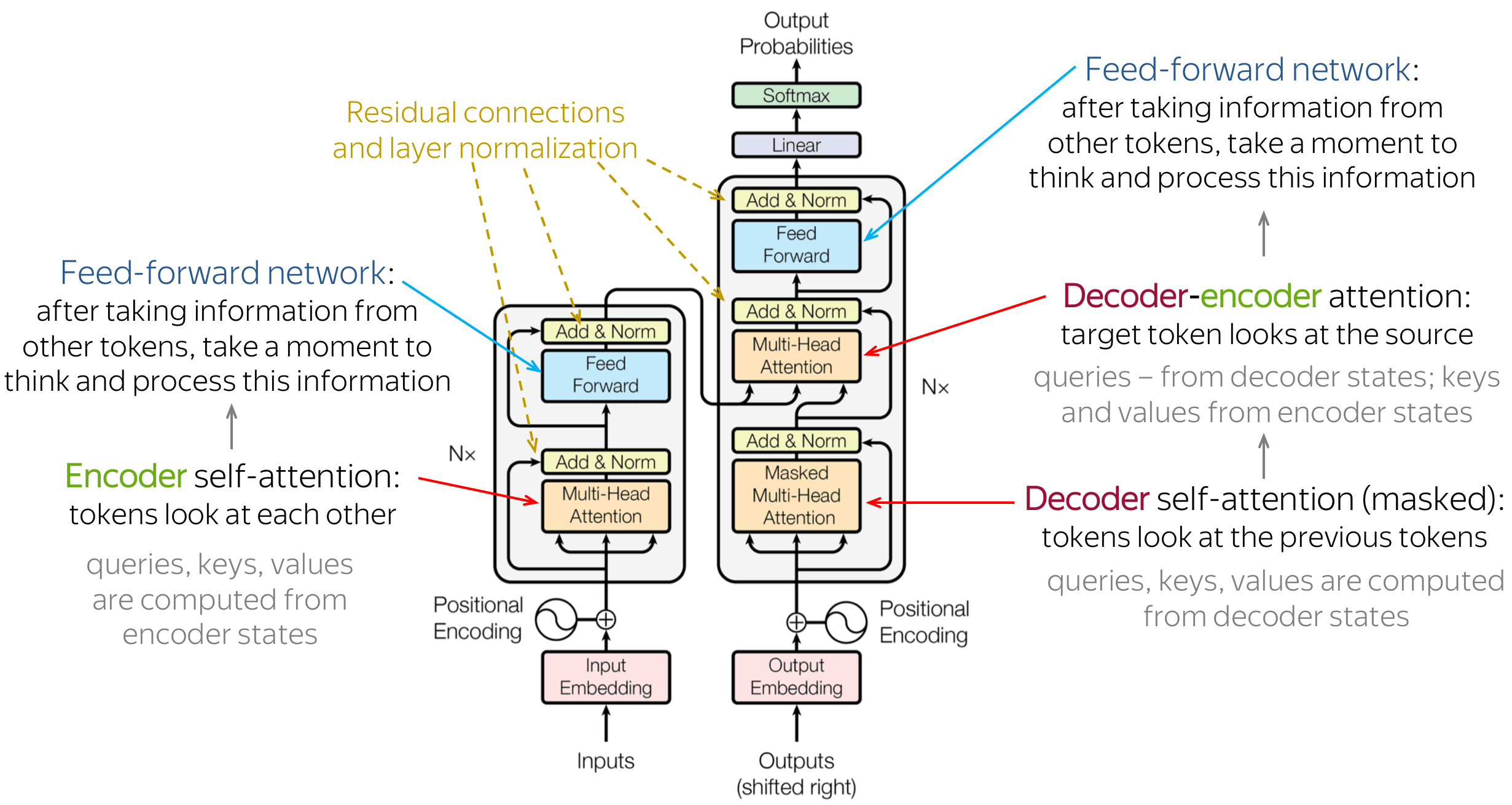
Zooming in on Attention 🔎
Visualizing Attention 👁️

Deconstructing Attention
Multi-head Attention
History of Attention

Transformers have driven
significant progress in AI

Decoder-only: GPT-1..4

Encoder-only: BERT and its progeny

Encoder-decoder: T5, BART

How is this all connected with GenAI?

Let's focus on the 'generative' part

There are 2 main classes of statistical models…
Discriminative models
draw boundaries in data space

{kind=link}
Example: Van Gogh or not Van Gogh? 👂🏻

Generative models
describe how data is placed
throughout the data space

Example: Picture me a 🐴
Since the model is probabilistic,
we can just sample from it to create new data

We can connect the two using Bayes' Rule

There are many types of generative models…

Overview of Generative Models

2013: Variational Autoencoders (VAE)

2014: Generative Adversarial Networks (GAN)

GAN Samples

2015: Diffusion Models

Diffusion takes a signal and turns it into noise
Signal $\rightarrow$ … $\rightarrow$ Noise

Diffusion models are trained to denoise noisy images

New images are created by
iteratively denoising pure noise
Noise $\rightarrow$ … $\rightarrow$ Signal

January 2021: OpenAI releases DALL-E

DALL-E Samples Comparison

July 2022: Midjourney enters open beta

AI-generated paintings as digital art
Théâtre d'Ópera Spatial (Midjourney + Gigapixel AI)

SPOILER ALERT GenAI and Hollywood 2.0
Learn how Runway helped create the rock scene 🪨 in
'Everything Everywhere All at Once.'

August 2022: Stability AI releases Stable Diffusion

Latent Diffusion Model Architecture
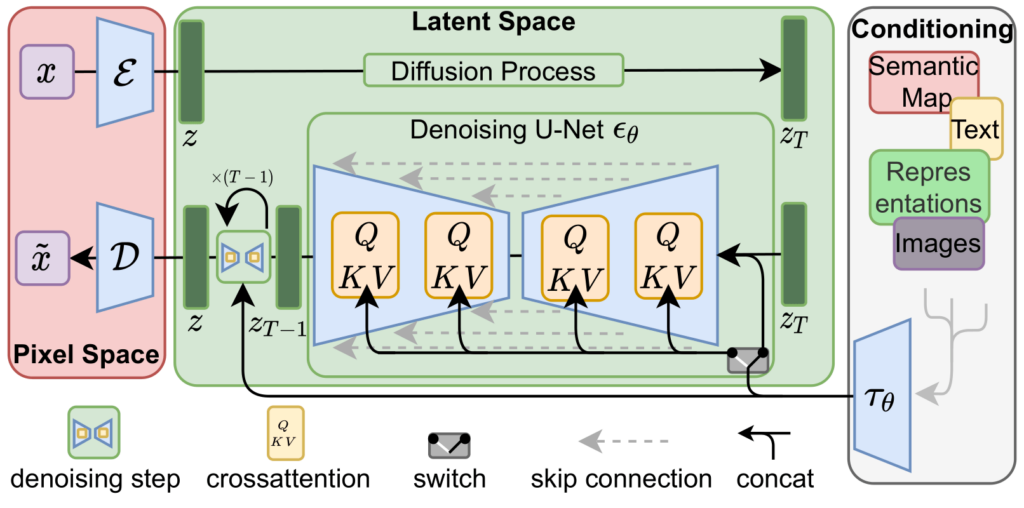
Stable Diffusion Components
January 2022: InstructGPT
Learning to follow instructions
from human preferences

November 2022: OpenAI releases ChatGPT

... and we're back!

So, where are we now...
and what's coming next?
GenAI is the fastest growing trend in AI
📈
The "Cambrian Explosion" of GenAI

Developer Adoption
Stable Diffusion accumulated
40k stars
on GitHub in its first 90 days

Consumer Adoption
ChatGPT reached the 1M users mark
in
just 5 days

GenAI according to GenAI

Let's break it down…

# 1
GenAI can generate new content
similar to what of a human would produce
Pop Quiz
Which painting was generated with AI?

If you answered A, you're in big trouble…
or was it the other way around? 🤔
# 2
GenAI is powered by Foundation Models
or FMs for short
These are really large models…
trained on massive amounts of unlabeled data…
that can be adapted to a wide range of tasks
Traditional vs Foundation Models

When dealing with natural language,
we usually talk about Large Language Models
or LLMs for short

Language modelling has been around for a while...

Word frequency vs Word Order

Series of approximations to English
| 0th-order approximation | XFOML RXKHRJFFJUJ ALPWXFWJXYJ FFJEYVJCQSGHYD QPAAMKBZAACIBZLKJQD |
| 1st-order approximation | OCRO HLO RGWR NMIELWIS EU LL NBNESEBYA TH EEI ALHENHTTPA OOBTTVA NAH BRL |
| 2nd-order approximation | ON IE ANTSOUTINYS ARE T INCTORE ST BE S DEAMY ACHIN D ILONASIVE TUCOOWE AT TEASONARE FUSO TIZIN ANDY TOBE SEACE CTISBE |
| 1st-order word approximation | REPRESENTING AND SPEEDILY IS AN GOOD APT OR COME CAN DIFFERENT NATURAL HERE HE THE A IN CAME THE TO OF TO EXPERT GRAY COME TO FURNISHES THE LINE MESSAGE HAD BE THESE |
| 2nd-order word approximation | THE HEAD AND IN FRONTAL ATTACK ON AN ENGLISH WRITER THAT THE CHARACTER OF THIS POINT IS THEREFORE ANOTHER METHOD FOR THE LETTERS THAT THE TIME OF WHO EVER TOLD THE PROBLEM FOR AN UNEXPECTED |
Source: Adapted from Shannon & Weaver(1963)
LLMs are really just a proper subset of FMs

Language modeling is compression

How do these models work?

If the input is text-based, we call it a Prompt

The Anatomy of a Prompt 💀
Prompts can be as simple as an instruction/question,
or as complex as huge chunks of text.
You can tell it who to be (role),
what it needs to know (context)
what to do (task) and how (instructions),
what it should avoid (constraints)
or you can show it what to do and how (examples)
There are no rules!
Role Prompting
Assign a role to the model
to provide some context

Few-Shot Prompting
Show the model a few examples
of what you want it to do

Crafting Prompts: Design Principles
- Clear and specific instructions
- Simple and clear wording
- Avoid complex sentence types
- Avoid ambiguity
- Use keywords
- Consider the audience
- Test and refine
Prompt Engineering 👩💻
Talking a model into doing
what you want it to do
Prompt Hacking 🐱💻
Talking a model into doing
something it's not supposed to
(either good or bad)
The hottest new programming language is English
― Andrej Karpathy, AI Researcher
How fluent are these models in other languages? 🗣️

# 3
GenAI applies to many use cases
Some examples include…
Productivity (Text Generation) 💬
Chat (Virtual Assistant) 💁
Summarization (Text Extraction) 📖
Search 🔎
Code Generation 👨💻
Music Creation 🎶
Video Editing 🎥
GenAI is rapidly transforming AI
Text-to-Image (txt2img)

Image-to-Text (img2txt)

Image-to-Image (img2img)

Text-to-GIF (txt2gif)

Text-to-Video (txt2video)

Text-to-Code (txt2code)
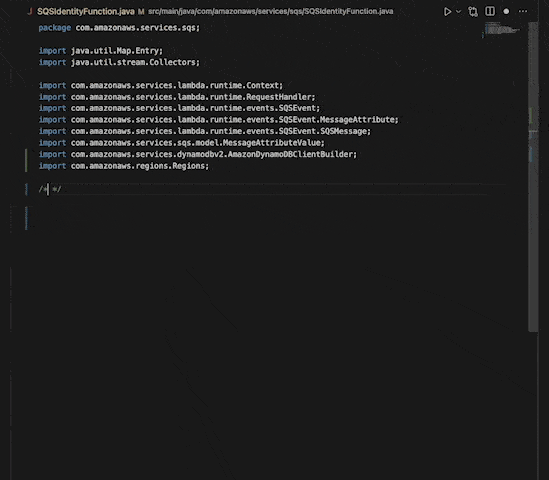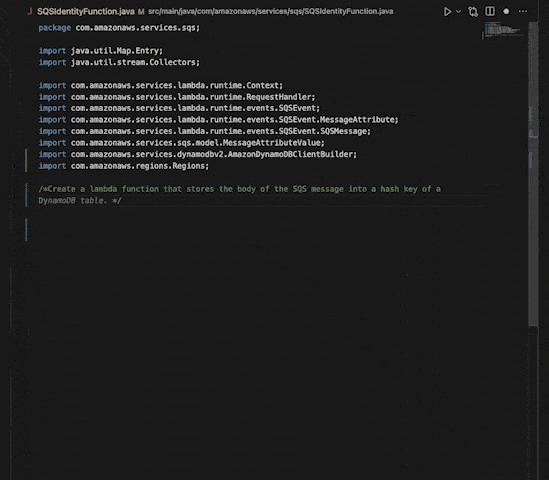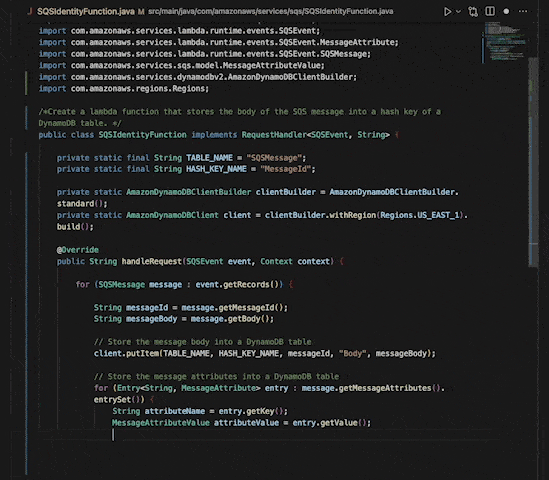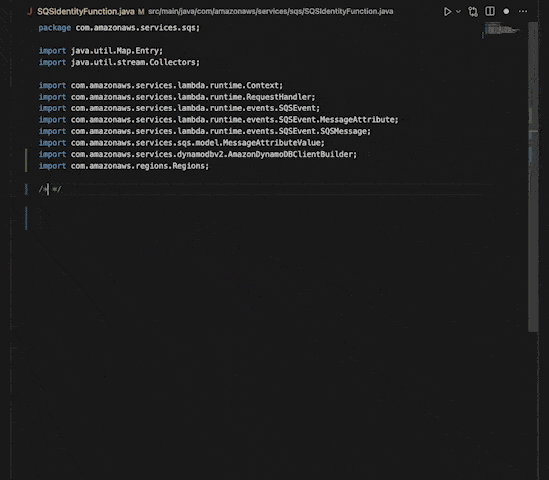
Generative Agents
")
Emergent Abilities: Just a Mirage? 🏝️
"(...) for a fixed task and a fixed model family, the researcher can choose a metric
to create an emergent ability or choose a metric to ablate an emergent ability"

GenAI is taking over the world

"Every industry that requires
humans to create original work (…)
is up for
reinvention."
But there are "some" challenges…
Hallucinations 🍄

Example: Backwards Epigenetic Inheritance
A causally impossible scientific theory
just a prompt away

"(…) they used to lie and say terrible things.
Now they just lie and that's
interesting enough"
― Gary Marcus
Actually…
Philosophically speaking,
LLMs are 🐂💩ers not liars
def. Bullshit
Any statement produced without
particular concern for reality and truth
"Bullshit is a greater enemy of truth than lies are."
― Harry Frankfurt, On Bullshit (2005)Why do these models hallucinate?
LLMs as "compact" and "lossy"
representations of knowledge

How can we prevent/reduce hallucinations?
RL with Human Feedback (RLHF)
Human evaluators review the model's responses and pick the most appropriate for the users' prompts

Can we take RL out of RLHF?
Direct Policy Optimization (DPO) bypasses both explicit reward estimation and RL and optimizes the language model directly using preference data.

Early Detection
Identify hallucinated content and
use it during training

Regularization
Often overlooked, these techniques
can help alleviate overfitting

Temperature Tuning 🌡️
Temperature regulates the randomness
or creativity of the responses

Chain-of-Thought (CoT) Reasoning 🤔
Using CoT prompting we can improve a model's ability to perform complex reasoning

External Data Sources
Provide access to relevant data from a knowledge base
Treat the task as a search problem grounded in data
Security 🛡️

Training LLMs on untrusted data
has become the norm rather than the exception

According to Wan et al. (2023), launching a successful data poisoning attack during instruction tuning
takes only a few hundred 'poisoned apples' 🍎☠️🤢

Prompt Attack
Attack that exploits the vulnerabilities of LLMs,
by manipulating their prompts

Adversarial Prompts

OWASP Top 10 for LLM Applications

Sustainability 🌱

Optimize workloads for environmental sustainability

The open source community
has a major role to play...
Let me tell you the story of Llama 🦙
February 24th 2023: Meta releases Llama 🦙

March 3rd 2023: LlaMALeaks 🤫

March 10th 2023: llama.cpp - initial release

March 12th 2023: LlaMA runs on a Raspberry Pi

March 13th 2023: Stanford releases Alpaca

Training recipe

Alpaca meets LoRA

Low-Rank Adaptation (LoRA)

Quantization
Rounding off one data type to another

Example: int8 absmax quantization

Quantized LoRA (QLoRA)
Introduces a number of innovations incl. Double Quantization and Paged Optimizers that save memory without compromising performance

March 14th 2023 🥧: LlaMA runs on a Pixel 6
March 19th 2023: LMSYS Org releases Vicuna

State of Llama in 2023/Q1

May 4th 2023 🌌🔫: Moats, moats, moats

July 18th 2023: Meta + Microsoft release Llama 2

August 24th 2023: Code Llama 👨💻🦙

September 27th 2023: AWS becomes the first managed API partner for Llama 2

Is Llama 2 open source?
No, and we need a new definition of open
Yes (citation needed)
NeurIPS LLM Efficiency Challenge
1 LLM 💬 + 1 GPU ⚡🌱 + 1 day ⏳
🐧
"I often compare open source to science. Science took this whole notion of developing ideas in the open and improving on other people's ideas. It made science what it is today and made the incredible advances that we have had possible."
― Linus TorvaldsWhat comes next?

Building GenAI on AWS

For more information, visit aws.amazon.com/generative-ai
GenAI Workloads

The AWS AI/ML Stack (Redux)
AWS supports GenAI in all layers of the stack

Let's start by looking at the bottom layer…
ML Frameworks & Infrastructure
There's some evidence that large-scale models
lead to better results*

* Read the fine print!
AI models are getting bigger…

… a lot bigger!

How do we train a large model like, say…
Stable Diffusion?

Let's check out Stability's HPC cluster 🦮
Training large-scale models comes
with a lot of challenges
Hardware 💻
Health Checks 👨⚕️⚠️
Orchestration 🎻🎶
Data 💾
Scale 📈
Cost 💰
HPC ML cluster for distributed training

1-click HPC

Compute: EC2 UltraClusters

Current NVIDIA A100 GPU Count

Compute: EC2 Trn1/Trn1n
Instances

Neuron on Trn1 Instances

Annapurna Labs
The 'Secret Sauce' behind AWS's success

Networking: Elastic Fabric Adapter (EFA)

Storage: ML training storage hierarchy

Orchestration: AWS Parallel Cluster

How to create a pcluster
pcluster create-cluster -f config.yaml ...

Is there a better way?

#1 Train Stable Diffusion on Amazon SageMaker

Step-by-Step Guide
-
Prepare Data
- Download
LAION-5BParquet files with SageMaker Processing Jobs - Download
LAION-5Bimages and text pairs - Create FSx for Lustre volume from S3 path
- Build JSON Lines index
- Download
-
Train Model
- Run on 192 GPUs with SageMaker distributed training
-
Evaluate Model
- 1 epoch on 50M image/text pairs with ~200 GPUs? 15 mins!
-
Deploy Model
- Run inference using SageMaker Hosting and evaluate results
Amazon SageMaker Studio

Amazon SageMaker Notebook Instance

FAQ: How much compute do I need?
Run the math! 🧮
Transformer FLOPS equation:
$6 \times \# parameters \times \# tokens$
Training
Transformer Math 101 by EleutherAIInference
Transformer Inference Arithmetic by KipplyWeight FLOPS Equation

FAQ: Which GPU is right for me?
Look at the whole system
Choose the right "GPU instance" not just the right "GPU"
Accelerate Transformers on AmazonSageMaker
with AWS Trainium and AWS Inferentia
Inf2 on Amazon SageMaker

Jupyter AI: Bring GenAI to Jupyter Notebooks

#2 Use a pre-trained FM
from Amazon SageMaker JumpStart

Models on Amazon SageMaker JumpStart can be accessed in 3 ways

Fine-tune Stable Diffusion
with Amazon SageMaker JumpStart
Benchmarking Stable Diffusion Fine-tuning Methods

Benefits of pre-trained FMs
-
Pre-trained models for each use case
-
Easy to customize + manage models at scale
-
Data is kept secure and private on AWS
-
Responsible AI support across ML lifecycle
-
Fully integrated with Amazon SageMaker
#3 Call Amazon Bedrock! ⛰️

Amazon Bedrock
API-level access to FMs

For more information, visit
aws.amazon.com/bedrock
Key Benefits

Bedrock supports a wide range of FMs

You are always in control of your data 🎛️

Bedrock/LangChain Integration ⛰️🦜🔗

Amazon CodeWhisperer
Build apps faster and more securely
with an AI coding companion

Open-source reference tracking
Security scanning

Multiple language and IDE support

"(…) participants who used CodeWhisperer were 27% more likely to complete tasks successfully and did so an average of 57% faster than those who didn't use CodeWhisperer."
― AWS News BlogBuild GenAI the easy way with managed services

Ready to learn how?

GenAI in Practice
Use Cases, Patterns & Solutions
🛠️
In just a few months, GenAI has exploded…

GenAI Landscape

By the time you read this,
the last slide will be completely…

Yet, some common patterns are starting to emerge…

Emerging LLM Patterns

Retrieval Augmented Generation (RAG)

Document Summarization

Document Generation with Facts

Emerging architectures for LLM applications

We can build all of these on AWS

RAG-based LLM-powered Q&A Bot

RAG workflow with Amazon Kendra and LangChain

Conversational Experience

Image-to-Speech
app using
Amazon SageMaker and 🤗

Virtual
fashion styling
using Amazon SageMaker 👒

Vector Databases

Vector databases are useful for storing embeddings
since they treat vectors as first class citizens
A Quick Primer on Embeddings
A numerical representation of a piece of information

Example: Embedding Wikipedia
What if you had the embeddings of ALL of Wikipedia?

How can AWS support your
vector database?
#1a RDS
for PgSQL + pgvector extension
CREATE TABLE test_embeddings(product_id bigint, embeddings vector(3) );
INSERT INTO test_embeddings VALUES
(1, '[1, 2, 3]'), (2, '[2, 3, 4]'), (3, '[7, 6, 8]'), (4, '[8, 6, 9]');
SELECT product_id, embeddings, embeddings <-> '[3,1,2]' AS distance
FROM test_embeddings
ORDER BY embeddings <-> '[3,1,2]';
/*
product_id | embeddings | distance
------------+------------+-------------------
1 | [1,2,3] | 2.449489742783178
2 | [2,3,4] | 3
3 | [7,6,8] | 8.774964387392123
4 | [8,6,9] | 9.9498743710662
*/
Use Case: Using
a similarity search for enhancing
product catalog search in an online retail store

#1b Aurora PgSQL + pgvector extension
# Adapted from
# https://github.com/aws-samples/aurora-postgresql-pgvector/tree/main/apgpgvector-streamlit
import streamlit as st
from dotenv import load_dotenv
from PyPDF2 import PdfReader
from langchain.embeddings import HuggingFaceInstructEmbeddings
from langchain.llms import HuggingFaceHub
from langchain.vectorstores.pgvector import PGVector
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from htmlTemplates import css, bot_template, user_template
from langchain.text_splitter import RecursiveCharacterTextSplitter
import os
# Load PDFs and split them into chunks
def get_pdf_text(pdf_docs):
text = ""
for pdf in pdf_docs:
pdf_reader = PdfReader(pdf)
for page in pdf_reader.pages:
text += page.extract_text()
return text
def get_text_chunks(text):
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ".", "!", "?", ",", " ", ""],
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text)
return chunks
# Load the embeddings into Aurora PostgreSQL DB cluster
CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver = os.environ.get("PGVECTOR_DRIVER"),
user = os.environ.get("PGVECTOR_USER"),
password = os.environ.get("PGVECTOR_PASSWORD"),
host = os.environ.get("PGVECTOR_HOST"),
port = os.environ.get("PGVECTOR_PORT"),
database = os.environ.get("PGVECTOR_DATABASE")
)
def get_vectorstore(text_chunks):
embeddings = HuggingFaceInstructEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
vectorstore = PGVector.from_texts(texts=text_chunks, embedding=embeddings,connection_string=CONNECTION_STRING)
return vectorstore
# Load the LLM and start a conversation chain
def get_conversation_chain(vectorstore):
llm = HuggingFaceHub(repo_id="google/flan-t5-xxl", model_kwargs={"temperature":0.5, "max_length":1024})
memory = ConversationBufferMemory(
memory_key='chat_history', return_messages=True)
conversation_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=vectorstore.as_retriever(),
memory=memory
)
return conversation_chain
# Handle user input and perform Q&A
def handle_userinput(user_question):
response = st.session_state.conversation({'question': user_question})
st.session_state.chat_history = response['chat_history']
for i, message in enumerate(st.session_state.chat_history):
if i % 2 == 0:
st.write(user_template.replace(
"{{MSG}}", message.content), unsafe_allow_html=True)
else:
st.write(bot_template.replace(
"{{MSG}}", message.content), unsafe_allow_html=True)
# Create Streamlit app
def main():
load_dotenv()
st.set_page_config(page_title="Streamlit Question Answering App",
page_icon=":books::parrot:")
st.write(css, unsafe_allow_html=True)
st.sidebar.markdown(
"""
### Instructions:
1. Browse and upload PDF files
2. Click Process
3. Type your question in the search bar to get more insights
"""
)
if "conversation" not in st.session_state:
st.session_state.conversation = None
if "chat_history" not in st.session_state:
st.session_state.chat_history = None
st.header("GenAI Q&A with pgvector and Amazon Aurora PostgreSQL :books::parrot:")
user_question = st.text_input("Ask a question about your documents:")
if user_question:
handle_userinput(user_question)
with st.sidebar:
st.subheader("Your documents")
pdf_docs = st.file_uploader(
"Upload your PDFs here and click on 'Process'", accept_multiple_files=True)
if st.button("Process"):
with st.spinner("Processing"):
# get pdf text
raw_text = get_pdf_text(pdf_docs)
# get the text chunks
text_chunks = get_text_chunks(raw_text)
# create vector store
vectorstore = get_vectorstore(text_chunks)
# create conversation chain
st.session_state.conversation = get_conversation_chain(
vectorstore)
if __name__ == '__main__':
main()
Use Case: AI-powered Chatbot

#2a OpenSearch
 is one of the most popular algorithms out there for Approximate Nearest Neighbor (ANN) search.")
Use Case: Amazon Music

#2b OpenSearch Serverless

#3 DynamoDB + Faiss
def save_faiss_model(self, text_list, id_list):
# Convert abstracts to vectors
embeddings = model.encode(text_list, show_progress_bar=False)
# Step 1: Change data type
embeddings32 = np.array(
[embedding for embedding in embeddings]).astype("float32")
# Step 4: Add vectors and their IDs
index_start_id = self.index.ntotal # inclusive
self.index.add(embeddings32)
index_end_id = self.index.ntotal # exclsuive
# serialize index
Path(f"{FAISS_DIR}/{self.content_group}").mkdir(parents=True, exist_ok=True)
faiss.write_index(self.index, f"{FAISS_DIR}/{self.content_group}/{self.content_group}_faiss_index.bin")
return (embeddings32, range(index_start_id, index_end_id))
Vector Library vs. Vector Database
Vector libraries are used to perform similarity search.
Examples: Facebook FAISS, Spotify Annoy, Google ScaNN, NMSLIB, Hnswlib
Vector databases are used to store and update data.
#4 Neptune ML

#5 AWS Marketplace Solution

#6 Other Solutions

It's really hard to take an application
from prototype to production.

Model Compression

LLM Evaluation
What, when and how to evaluate

LLMOps Workflow

Monitoring GenAI Models

GenAI applications can be very powerful,
but also very vulnerable.

How can we protect users
against manipulation and abuse
while creating a safe and positive experience?
GenAI meets Amazon AI content moderation services

What comes next?

LLM OS

LLM Compiler

What if I want to explore
more use cases?

AI Use Case Explorer
Find the most relevant AI use cases with
related content and guidance to make them real

Generative AI Atlas
Public repository with the newest content
released by AWS on GenAI

github.com/aws-samples/gen-ai-atlas
Machine Learning University 🎓
For a set of fun and interactive explanations
of core ML concepts, check out MLU Explain

Hello World: Meet Generative AI
Werner Vogels and Swami Sivasubramanian
sit down to discuss GenAI and why it's not a hype
AWS DeepComposer: AI Music Composer
Follow the Music 🎶
Hands-On GenAI with LLMs Course
Learn the fundamentals of how GenAI works and
how to deploy it in real-world applications

AWS GenAI Chatbot Platform
Deploy a multi-LLM and multi-RAG powered chatbot using AWS CDK

AWS Generative AI Accelerator
Accelerate your GenAI startup in 10 weeks

References 📚

General
- Intro to LLMs by Andrej Karpathy
- What Is ChatGPT Doing … and Why Does It Work? by Stephen Wolfram
- Catching up on the weird world of LLMs by Simon Willison
Transformers 🚗🤖⚔️
- The original paper by Vaswani et al.
- The annotated version by Harvard NLP
- The illustrated version by Jay Alammar
- The Twitter version by
abhi1thakur,MishaLaskinand0xsanny
Diffusers 🧨
- The original paper by Ho et al.
- The annotated version by 🤗
- The illustrated version by Jay Alammar
- The Twitter
version by
iScienceLuvr
Courses 👩🏫
- ALAFF: Advanced Linear Algebra - Foundations to Frontiers
- Statistics 110: Probability
- CS221: Artificial Intelligence - Principles and Techniques
- CS25: Transformers United
- COS597G: Understanding Large Language Models
- CS224N: Natural Language Processing with Deep Learning
- CS224U: Natural Language Understanding
- CS324: Large Language Models
- CS685: Advanced Natural Language Processing
- 263-5354-00L: Large Language Models
Miscellaneous 👾
Note: The emphasis is on breadth, not depth
- Neural Networks: Zero to Hero by Andrej Karpathy
- NLP Course by 🤗
- LangChain for LLM Application Development by DeepLearning.ai
- Large Language Model Course
by
mlabonne - Learn Prompting
- Testing GPT-based apps by Jason Arbon
- LLM Economics by Skanda Vivek
Meta ♾️
Disclaimer: I take no responsibility for the content available through these links
- Understanding LLMs - A Transformative Reading List by Sebastian Raschka
- LLMs Practical Guide
by
Mooler0410 - Awesome GPT Security
by
cckuailong - Awesome LLM
by
Hannibal046 - Awesome LangChain by Kyrolabs
- AI Canon by Andreessen Horowitz
- aman.ai by Aman Chada